说明
- 本文是用作2017-12-03晚晚茶会的试讲大纲。
- 由于晚茶会时间有限,本文目的是做成一个60分钟t-SNE闪电入门简介,可能无法详细讲解原理,学术帝请移步我的另一篇博文:论文笔记:Visualizing data using t-SNE
基础篇
认识高维空间:维数灾难
维数灾难(curse of dimensionality)描述的是高维空间中若干迥异于低维空间、甚至反直觉的现象。该现象的详细论述可以参考文献1,其中通过超立方体和其内切球的推导十分精彩,这里不再赘述。
高维空间中数据样本极其稀疏。需要维度几何级数的数据才能满足在高维空间密采样(dense sample)。反过来,高维数据降维到低维空间也将发生“拥挤问题(Crowding Problem)2”
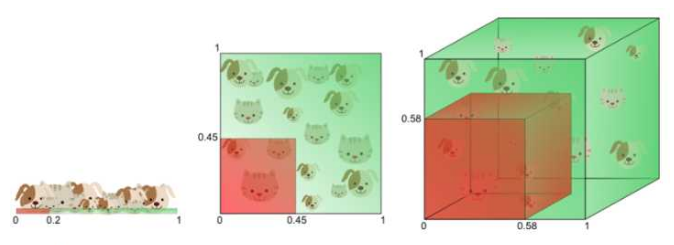
高维单位空间中数据几乎全部位于超立方体的边缘。
几何学能给出高维空间中超几何体的体积,单位超立方体的体积\(V_{hypercube} = 1^d = 1\),而其内切超球体的体积公式如下:
\[V_{hypersphere} = \frac{\pi^{\frac{n}{2}}}{\Gamma(\frac{n}{2} + 1)}\cdot 0.5^d\]
对两者商做极限\(\lim_{d \to +\infty}\frac{V_{hypersphere}}{V_{hypercube}}=0\),因此可以说一个高维单元空间只有边角,而没有中心。数据也只能处于边缘上,而远离中心。这样就直接导致了下一个性质:
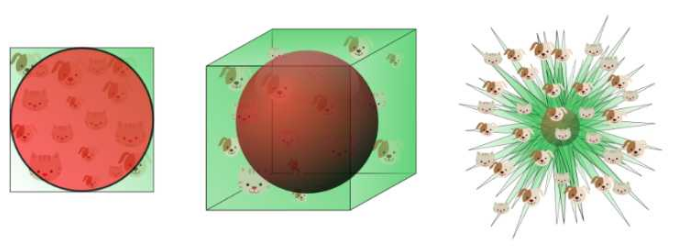
欧氏距离失效(因此任何基于欧氏距离的算法也失效)。
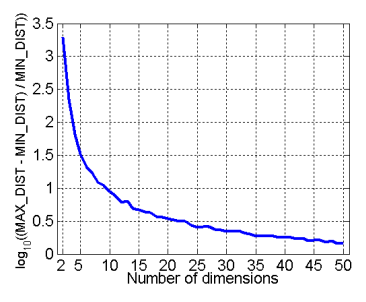
上图描述的是高维空间中大距离和小距离的差异越来越不明显。
\[\lim_{d\to +\infty}\frac{dist_{max} - dist_{min}}{d_{min}}=0\]
这是由上一性质自然推导出的结论。
降维
- 降维(dimension reduction)的基本作用:
- 缓解维数灾难。即提高样本密度,以及使基于欧氏距离的算法重新生效。
- 数据预处理。对数据去冗余、降低信噪比。
- 方便可视化。
- 降维的概念中有两对直觉性的概念会反复出现:高维/低维空间、高维/低维数据。在文献中他们有若干别称3:
- 高维空间(high-dimensional space),又叫原空间(original space)
- 高维数据(low-dimensional data),也直接叫数据点(data points),用于和下述的映射点对应。
- 低维空间(low-dimensional space),又叫嵌入空间(embedded space)、低维映射(low-dimensional map,map在此做名词用)等
- 低维数据(low-dimensional data),又叫低维嵌入(low-dimensional embeddings)、低维表示(low-dimensional representations)、映射点(map points)等
- 嵌入(embedding):数学上,嵌入是指一个数学结构经映射包含在另一个结构中。
- NLP目前所使用的词嵌入(word embedding)一词的本意可能就是这个意思。最初所使用的词向量是one-hot向量,维度等于词表大小(约几十万)。后来采用分布式表示的词向量,维度一般取几百维。因此我们认为分布式表示的词向量是更高维度语义空间的低维嵌入(embedding)。
- “Embed Everything!” 嵌入的思想不仅可以用在词(word)上,还能用于许多其他技术上。如知识图谱中可以把原先的网络结构也做嵌入,有实体嵌入、关系嵌入等。
- 降维技术可以分为线性和非线性两大类:
- 线性降维技术。侧重让不相似的点在低维表示中分开。
- PCA(Principle Components Analysis,主成分分析)
- MDS(Multiple Dimensional Scaling,多维缩放)等
- 非线性降维技术(广义上“非线性降维技术”≈“流形学习”,狭义上后者是前者子集)。这类技术假设高维数据实际上处于一个比所处空间维度低的非线性流形上,因此侧重让相似的近邻点在低维表示中靠近。
- Sammon mapping
- SNE(Stochastic Neighbor Embedding,随机近邻嵌入),t-SNE是基于SNE的。
- Isomap(Isometric Mapping,等度量映射)
- MVU(Maximum Variance Unfolding)
- LLE(Locally Linear Embedding,局部线性嵌入)等
- 线性降维技术。侧重让不相似的点在低维表示中分开。
流形学习
- 流形(manifold):
- 机器学习中指的流形指本征维度较低但嵌入在高维空间中的空间(a manifold has low intrinsic dimensions, and is embedded within a space of much higher dimensionality4)。比如上图中的S-curve数据集,本征维度=2(摊开来是一个二维空间),但被嵌在三维空间中。
- 数学中提到流形,强调其具有局部欧式空间的性质,可以在局部应用欧几里得距离。但是在机器学习(流形学习)中,这个假设基本不成立。原因是高维空间由于维数灾难的存在,没有足够稠密的数据能在足够小的局部去近似该流形5。
- 但是流形概念中局部的思想仍可以借鉴。它为降维提供了另一个视角:从微观角度去探索高维数据结构。
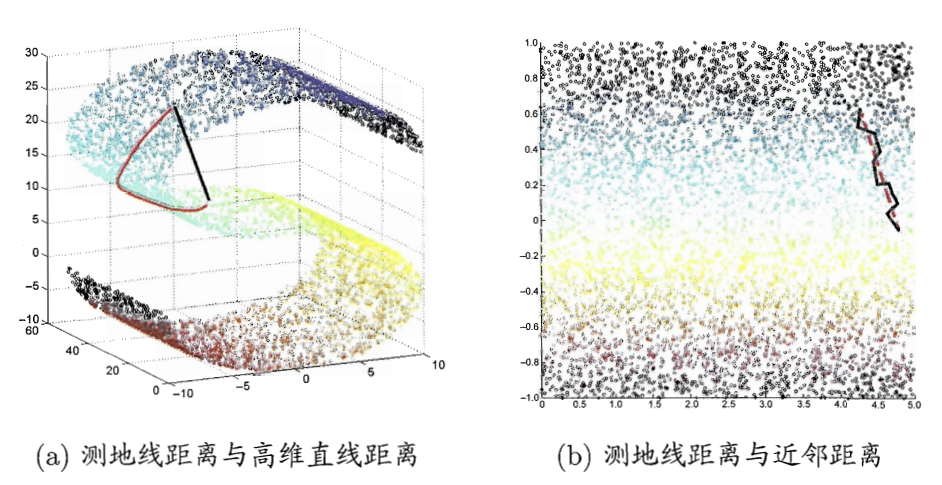
- 距离6:想象你是一只蚂蚁,在图中的二维曲面流形上行走。
- 高维直线距离:左图黑线。这个距离没有意义!
- 测地线距离:左图红线,右图红虚线。这个距离才有意义!
- 近邻距离:右图黑折线。用近邻距离可以拟合测地线距离。
- 学习:流形学习之所以叫学习,因为它不像PCA一类的纯线性代数降维方法,而是更像一个类似神经网络的学习算法。
- 神经网络大部分是有监督学习;流形学习大部分是无监督学习。
- 神经网络拟合一个分类函数;流形学习(以t-SNE为例)拟合高维数据的分布。
- 神经网络学习参数;流形学习(以t-SNE为例)直接学习低维数据的表达。
- 两者均有损失函数、梯度下降、迭代轮数等学习算法的特点。
学术篇
SNE
SNE(Stochastic Neighbor Embedding,随机近邻嵌入)7
SNE两个主要思路/步骤:
- 将欧氏距离转化为条件概率来表征点间相似度(pairwise similarity)。
- 使用梯度下降算法来使低维分布学习/拟合高维分布。
给定高维空间的数据点\(x_1, x_2, ..., x_n\),\(p_{i|j}\)是\(x_i\)以自己为中心,以高斯分布选择\(x_j\)作为近邻点的条件概率。
\[p_{j|i} = \frac{exp(-||x_i-x_j||^2/2\sigma_i^2)}{\sum_{k\neq i}exp(-||x_i-x_k||^2/2\sigma_i^2)}\]
注意:1)对除i外其他所有j都计算一个条件概率后,形成一个概率分布列,所以分母需要归一化。2)默认\(p_{i|i}=0\)。3)每不同数据点\(x_i\)有不同的\(\sigma_i\),在此不展开。
同理,有低维空间的映射点\(y_1, y_2, …, y_n\)(分别对应\(x_1, x_2, ..., x_n\)),\(q_{j|i}\)是\(y_i\)以自己为中心,以高斯分布选择\(y_j\)作为近邻点的条件概率。
\[q_{j|i} = \frac{exp(-||y_i-y_j||^2)}{\sum_{k\neq i}exp(-||y_i-y_k||^2)}\]
注意:这里方差统一取\(\sigma_i=1/\sqrt{2}\),若方差取其他值,对结果影响仅仅是缩放而已。
SNE的目标是让低维分布去拟合高维分布,则目标是令两个分布一致。两个分布的一致程度可以使用相对熵(Mutual entropy,也叫做KL散度,Kullback-Leibler divergences,KLD)来衡量,可以以此定义代价函数(cost function):
\[C=\sum_i KL(P_i||Q_i) = \sum_i \sum_j p_{j|i} log\frac{p_{j|i}}{q_{j|i}}\]
其中 \(P_i(k=j)=p_{j|i}\) 和 \(Q_i(k=j)=q_{j|i}\) 是两个分布列。
注意:KLD是不对称的!因为 \(KLD=p log(\frac{p}{q})\),p>q时为正,p<q时为负。则如果高维数据相邻而低维数据分开(即p大q小),则cost很大;相反,如果高维数据分开而低维数据相邻(即p小q大),则cost很小。所以SNE倾向于保留高维数据的局部结构。
对\(C\)进行梯度下降即可以学习到合适的\(y_i\)。
梯度公式:
\[\frac{\partial C}{\partial y_i} = 2 \sum_j (p_{j|i} - q_{j|i} + p_{i|j} - q_{i|j})(y_i - y_j)\]
带动量的梯度更新公式:(这里给出单个\(y_i\)点的梯度下降公式,显然需要对所有\(\mathcal{Y}^{(T)}=\{y_1, y_2, ..., y_n\}\)进行统一迭代。)
\[y_i^{(t)} = y_i^{(t-1)} + \eta \frac{\partial C}{\partial y_i} + \alpha(t)( y_i^{(t-1)} - y_i^{(t-2)})\]
t-SNE
t-Distributed Stochastic Neighbor Embedding8
事实上SNE并没有解决维度灾难带来的若干问题:
拥挤问题(Crowding Problem):在二维映射空间中,能容纳(高维空间中的)中等距离间隔点的空间,不会比能容纳(高维空间中的)相近点的空间大太多。9
换言之,哪怕高维空间中离得较远的点,在低维空间中留不出这么多空间来映射。于是到最后高维空间中的点,尤其是远距离和中等距离的点,在低维空间中统统被塞在了一起,这就叫做“拥挤问题(Crowding Problem)”。
拥挤问题带来的一个直接后果,就是高维空间中分离的簇,在低维中被分的不明显(但是可以分成一个个区块)。比如用SNE去可视化MNIST数据集的结果如下:

如何解决?高维空间保持高斯分布不变,将低维空间的分布做调整,使得两边尾巴比高维空间的高斯分布更高,即可缓解拥挤问题。想一想为什么?(在下面t-分布中解释)
- UNI-SNE10:给低维空间的点给予一个均匀分布(uniform dist),使得对于高维空间中距离较远的点(\(p_{ij}\)较小),强制保证在低维空间中\(q_{ij}>p_{ij}\) (因为均匀分布的两边比高斯分布的两边高出太多了)。
t-分布(Student’s t-distribution)
t-分布的概率密度函数(probability density function,PDF)形式为:
\[f(t) = \frac{\Gamma(\frac{\nu + 1}{2})}{\sqrt{\nu \pi}\Gamma(\frac{\nu}{2})}(1 + \frac{t^2}{\nu})^{-\frac{\nu + 1}{2}}\]
其中 \(\nu\) 是自由度。
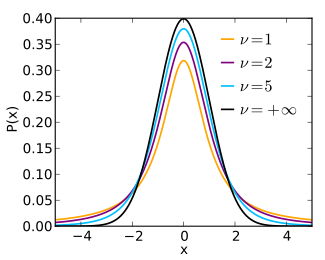
figure of probability density function
当 \(\nu = 1\)
\[f(t) = \frac{1}{\pi (1+t^2)}\]
叫做柯西分布(Cauchy distribution),我们用到是这个简单形式。
当 \(\nu = \infty\)
\[f(t) = \frac{1}{\sqrt{2\pi}} e^{-\frac{t^2}{2}}\]
叫做高斯/正态分布(Guassian/Normal distribution)。
我们在低维空间的分布中,把原先用的高斯分布改成自由度为1的分布(把尾巴抬高)。下图可以很好地说明为什么“把尾巴抬高”可以很好地缓解拥挤问题。绘图代码参考11

假设我们的低维数据分布对高维数据分布已经拟合完毕,则可以认为对于高维数据点\(x_i\)、\(x_j\)和低维映射点\(y_i\)、\(y_j\),有\(p_{ij}=q_{ij}\)。我们用图中两条红线表示两种情况:
- 上面的红线表示:当两个点相距相对近的时候,低维空间中比高维空间中相对更近。
- 下面的红线表示:当两个点相距相对远的时候,低维空间中比高维空间中相对更远。
可以对比一下采用t-SNE对MNIST数据集的降维可视化效果
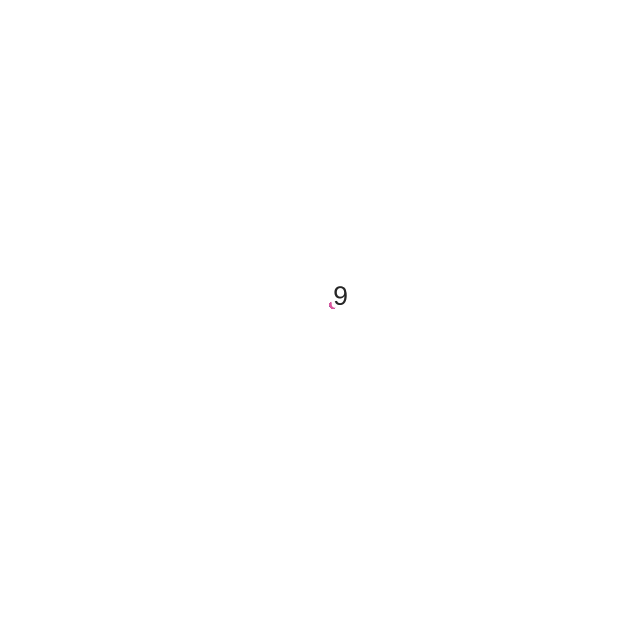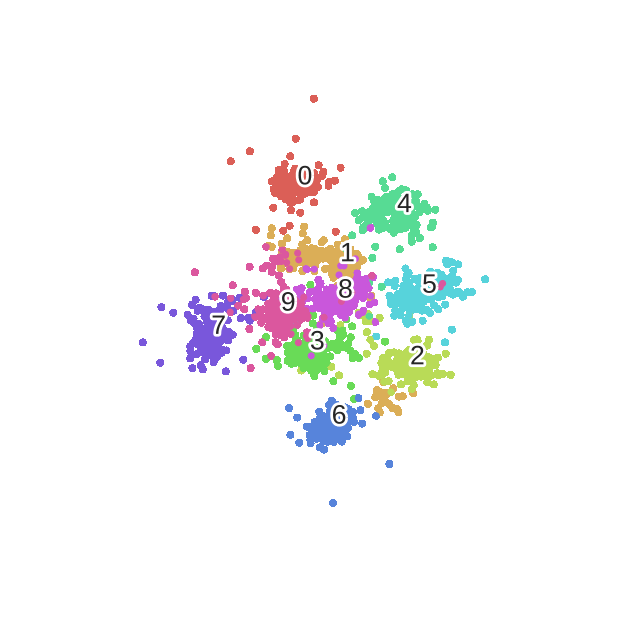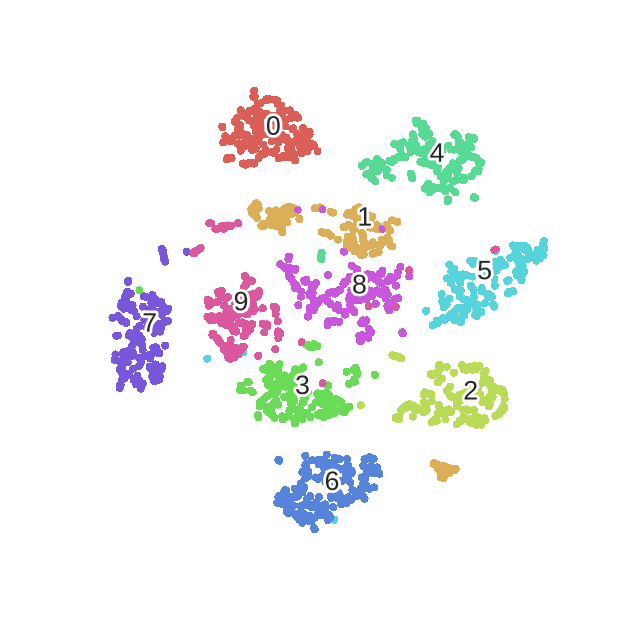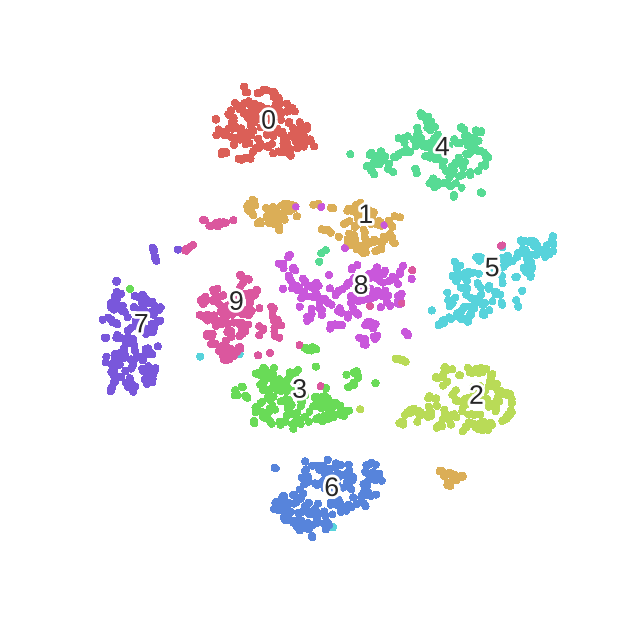
以上是t-SNE的主要思想,其余还有若干知识点(如对称SNE、优化的技巧等),请参考论文12或者我的另一篇博文:论文笔记:Visualizing data using t-SNE。
工程篇
Python库:sklearn.manifold
推荐阅读Python下著名的机器学习库scikit-learn的相应文档:
sklearn.manifold.TSNE- scikit-learn
困惑度
使用t-SNE时,除了指定你想要降维的维度(参数
n_components),另一个重要的参数是困惑度(Perplexity,参数perplexity)。困惑度大致表示如何在局部或者全局位面上平衡关注点,再说的具体一点就是关于对每个点周围邻居数量猜测。困惑度对最终成图有着复杂的影响。
前面提到高维空间中每一个数据点\(x_i\)的高斯分布中的方差\(\sigma_i\)都必须设为不同。该方差\(\sigma_i\)须具有如下性质:在数据密集的地方要小,数据稀疏的地方要大。显然\(\sigma_i\)和困惑度有着相关关系。
如何给每个\(x_i\)分配\(\sigma_i\)值呢?
使用算法来确定\(\sigma_i\)则要求用户预设困惑度。然后算法找到合适的\(\sigma_i\)值让条件分布\(P_i\)的困惑度等于用户预定义的困惑度即可。
\(Perp(P_i) = 2^{H(P_i)} = 2^{-\sum_j p_{j|i} log_2 p_{j|i}}\)
注意:困惑度设的大,则显然\(\sigma_i\)也大。两者是单调关系,因此可以使用二分查找。
论文16建议困惑度设为5-50比较好。这还是一个很大的范围,事实上在这个范围内,调节困惑度可以展示从微观到宏观的一系列视角,见下一节。
可视化
日常使用t-SNE可调的参数基本只有困惑度,非常简单。针对困惑度如何影响可视化结果,文献17做了非常详细的展示,还包含一个在线程序可以辅助认识。
文献18给出的基本结论如下:
- 簇(cluster)的大小无关紧要。
- 簇之间的距离无关紧要。
- 密集的区域会被扩大,稀疏的区域会被缩小。等
根据文献19给的图,说一点自己的理解:
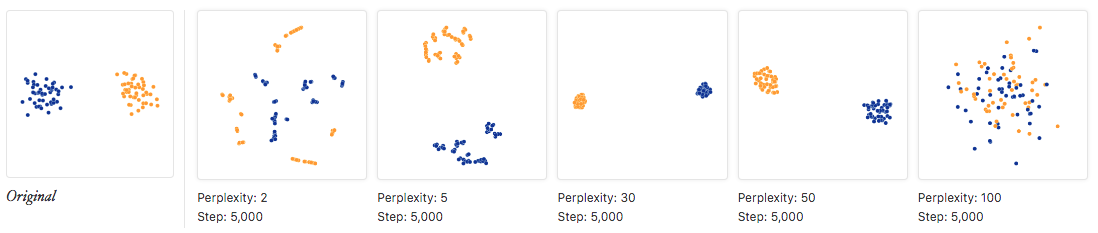


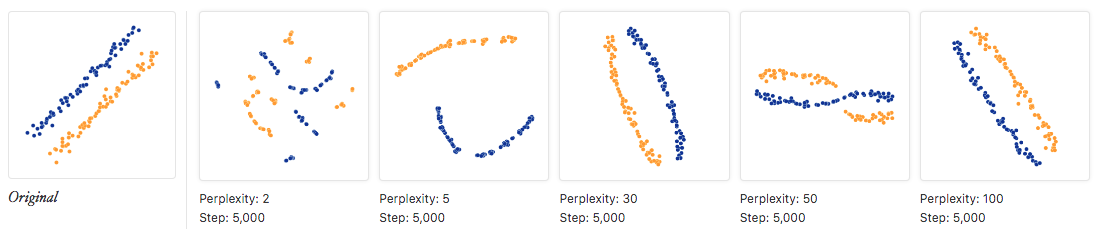

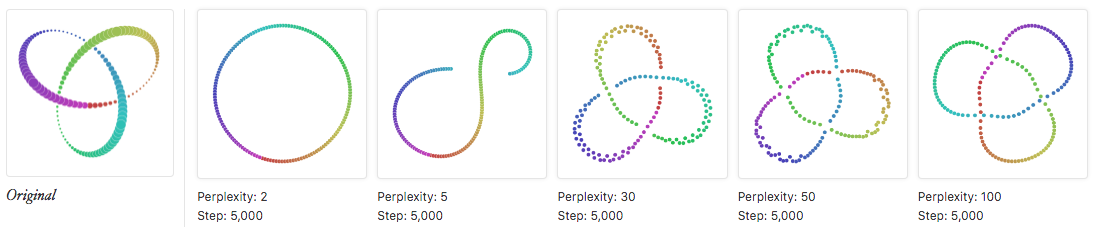
- 低困惑度对应的是局部视角,要把自己想象成一只蚂蚁,在数据所在的流形上一个点一个点地探索。
- 高困惑度对应的是全局视角,要把自己想象成上帝。
t-SNE优点
- 流形学习中其他方法如Isomap、LLE等,主要用于展开单个连续的低维流形(比如“瑞士卷”数据集),而t-SNE主要用于数据的局部结构,并且会倾向于提取出局部的簇,这种能力对于可视化同时包含多个流形的高维数据(比如MNIST数据集)很有效。
t-SNE缺点
- 时间、空间复杂度为\(O(n^2)\),计算代价昂贵。百万量级的数据需要几小时,对于PCA可能只需要几分钟。
- 升级版Barnes-Hut t-SNE可以让复杂度降为\(O(nlogn)\),但只限于获得二维和三维的嵌入。(sklearn中可以直接使用参数
method=’barnes_hut’) - 由于代价函数非凸,多次执行算法的结果是随机的(名字中“Stochatsic”的由来?),需要多次运行选取最好的结果。
- 全局结构不能很清楚的保留。这个问题可以通过先用PCA降维到一个合理的维度(如50)后再用t-SNE来缓解,前置的PCA步骤也可以起到去除噪声等功能,。(sklearn中可以直接使用参数
init='pca')
尾声
这次褐蚁来到故地,只是觅食途中偶然路过而已。它来到孤峰脚下,用触须摸了摸这顶天立地的存在,发现孤峰的表面坚硬光滑,但能爬上去,于是它向上爬去。没有什么且的,只是那小小的简陋神经网络中的一次随机扰动所致。这扰动随处可见,在地面的每一株小草和草叶上的每一粒露珠中,在天空中的每一片云和云后的每一颗星辰上……扰动都是无目的的,但巨量的无目的扰动汇集在一起,目的就出现了。…
与此同时,在前方的峭壁上,它遇到了一道长长的沟槽,与峭壁表面相比,沟槽的凹面粗糙一些,颜色也不同,呈灰白色,它沿着沟槽爬,粗糙的表面使攀登容易了许多。沟槽的两端都有短小的细槽。下端的细槽与主槽垂直,上端的细槽则与主槽成一个角度相交。当褐蚁重新踏上峭壁光滑的黑色表面后,它对槽的整体形状有了一个印象:“1”。…
很快,它遇到了另一道沟槽,它很留恋沟槽那粗糙的凹面,在上面爬行感觉很好,同时槽面的颜色也让它想起了蚁后周围的蚁卵。它不惜向下走回头路,沿着槽爬了一趟。这道槽的形状要复杂些,很弯曲,转了一个完整的圈后再向下延伸一段,让它想起在对气味信息的搜寻后终于找到了回家的路的过程,它在自己的神经网络中建立起了它的形状:“9”。…
褐蚁继续沿着与地面平行的方向爬,进入了第三道沟槽,它是一个近似于直角的转弯,是这样的:“7”。它不喜欢这形状,平时,这种不平滑的、突然的转向,往往意味着危险和战斗。…
孤峰上的褐蚁本来想转向向上攀登,但发现前面还有一道凹槽,同在“7”之前爬过的那个它喜欢的形状“9”一模一样,它就再横行过去,爬了一遍这个“9”。它觉得这个形状比“7”和“1”好,好在哪里当然说不清,这是美感的原始单细胞态;刚才爬过“9”时的那种模糊的愉悦感再次加强了,这是幸福的原始单细胞态。但这两种精神的单细胞没有进化的机会,现在同一亿年前一样,同一亿年后也一样。
——《三体II 黑暗森林》,刘慈欣 著
参考文献
Maaten, L. V. D., & Hinton, G. (2008). Visualizing data using t-SNE. Journal of Machine Learning Research, 9(Nov), 2579-2605. [pdf]↩
Maaten, L. V. D., & Hinton, G. (2008). Visualizing data using t-SNE. Journal of Machine Learning Research, 9(Nov), 2579-2605. [pdf]↩
Maaten, L. V. D., & Hinton, G. (2008). Visualizing data using t-SNE. Journal of Machine Learning Research, 9(Nov), 2579-2605. [pdf]↩
周志华. 机器学习. 第10章.↩
Hinton, G. E., & Roweis, S. T. (2003). Stochastic neighbor embedding. In Advances in neural information processing systems (pp. 857-864). [pdf]↩
Maaten, L. V. D., & Hinton, G. (2008). Visualizing data using t-SNE. Journal of Machine Learning Research, 9(Nov), 2579-2605. [pdf]↩
Maaten, L. V. D., & Hinton, G. (2008). Visualizing data using t-SNE. Journal of Machine Learning Research, 9(Nov), 2579-2605. [pdf]↩
Cook, J., Sutskever, I., Mnih, A., & Hinton, G. (2007, March). Visualizing similarity data with a mixture of maps. In Artificial Intelligence and Statistics (pp. 67-74). [pdf]↩
Maaten, L. V. D., & Hinton, G. (2008). Visualizing data using t-SNE. Journal of Machine Learning Research, 9(Nov), 2579-2605. [pdf]↩
Hinton, G. E., & Roweis, S. T. (2003). Stochastic neighbor embedding. In Advances in neural information processing systems (pp. 857-864). [pdf]↩
Hinton, G. E., & Roweis, S. T. (2003). Stochastic neighbor embedding. In Advances in neural information processing systems (pp. 857-864). [pdf]↩
Van Der Maaten, L. (2014). Accelerating t-SNE using tree-based algorithms. Journal of machine learning research, 15(1), 3221-3245. [pdf]↩
Maaten, L. V. D., & Hinton, G. (2008). Visualizing data using t-SNE. Journal of Machine Learning Research, 9(Nov), 2579-2605. [pdf]↩
Wattenberg, M., Viégas, F., & Johnson, I. (2016). How to Use t-SNE Effectively. Distill, 1(10), e2. [html]↩
Wattenberg, M., Viégas, F., & Johnson, I. (2016). How to Use t-SNE Effectively. Distill, 1(10), e2. [html]↩
Wattenberg, M., Viégas, F., & Johnson, I. (2016). How to Use t-SNE Effectively. Distill, 1(10), e2. [html]↩